3-way Superscalar R10K Out-of-Order (OoO) RISC-V Processor Design
Abstract
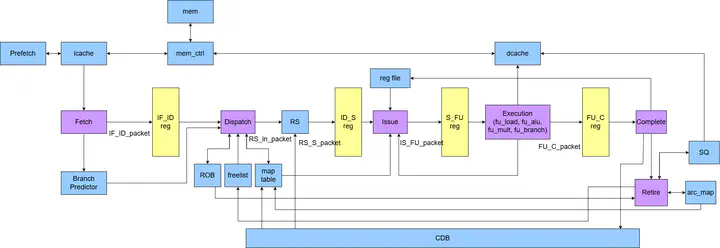
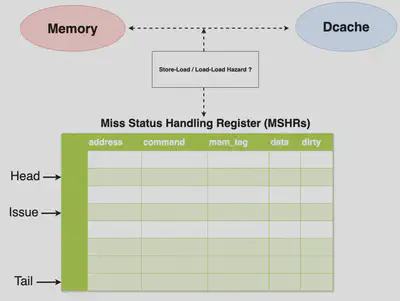
This project presents the design and implementation of an R10K out-of-order processor supporting a 3-way superscalar pipeline with advanced microarchitectural features. Key components include a Reorder Buffer (ROB), Freelist, Reservation Station (RS), physical register management (MapTable and Architecture Map), and an enhanced Gshare branch predictor. Further optimizations such as Instruction Prefetch, Store Queue, and an Advanced Data Cache are integrated to improve performance. The processor successfully executes all 33 benchmark instructions provided in the course,achieving full functional correctness in simulation and synthesis. Performance analysis shows an average CPI (Cycles Per Instruction) of 2.826, with a minimum synthesizable clock period of 11.2 ns and an average TPI (Time Per Instruction) of 31.651 ns. These results demonstrate the efficiency of our design in balancing complexity and speed while maintaining correctness in a multi-issue, out-of-order execution environment.
DESIGN DETAILS
Dataflow Block Diagram: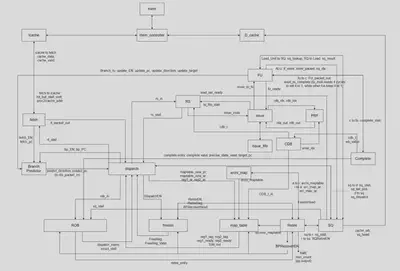
PERFORMANCE
Average CPI: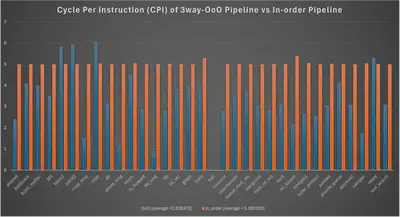
Links
Please find more details in Github, Final Report, and Slides.
Yuan Jiang
ASIC Design & DV
I’m currently actively seeking new graduate full-time opportunities in ASIC Design Verification and RTL Design, and I’d be excited to explore roles that align with my background.